This is the #TidyTuesday data for 8/25/20
This is my very first attempt at a Tidy Tuesday Challenge. I have been learning R for a little over a year. I’ve known about Tidy Tuesday, but I never felt comfortable enough with my programming knowledge to actually attempt it. I’ve finally came to the conclusion that it doesn’t matter where you are in your coding journey, you just need to step outside the box and go for it. I also finally read R for Data Science by Hadley Wickham and Garrett Grolemund. It taught me a lot of important information to at least start off on the right foot and see what I can do. I’m also currently enrolled in an Exploratory Data Analysis class at Indiana University as part of my Master of Statistics program. We use the tidyverse quite a bit and are even referenced the R4DS book from time to time. I’m excited to begin so here we go. I will try to give as much commentary as I can along the way as I think about the direction I want to take this data.
First thing is first. Let’s load the tidyverse library and retrieve the data for this week’s Tidy Tuesday data. Typically, I load all libraries in the first chunk, but since I am doing a commentary, I will load as I go. Also, I will get the data through the tidytuesdayR library. (Pro tip: Use snippets! tv then (shift + tab) populates library(tidyverse) and r then (shift + tab) populates a new r chunk. Very handy!)
# install.packages("tidyverse")
library(tidyverse)## ── Attaching packages ──────────────────────────────────────────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.1 ✓ purrr 0.3.4
## ✓ tibble 3.0.1 ✓ dplyr 1.0.0
## ✓ tidyr 1.1.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ─────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()# install.packages("tidytuesdayR")
library(tidytuesdayR)## Warning: package 'tidytuesdayR' was built under R version 4.0.2In future weeks, I will likely use the template that comes with the tidytuesdayR package, but for my first attempt, I will use my own organization structure. The template can be used as follows:
tidytuesdayR::use_tidytemplate(name = "My Super Great TidyTuesday.Rmd")There are some useful techniques to use from this template. One being putting eval = interactive() in the chunk to learn more about the data for the week. We are ready to retrieve the data and learn more about it.
# tt <- tt_load("2020-8-25")
tt <- read_rds("tt-8-25-20.rds")ttThis week’s data is about a show called Chopped. This is a cooking show where four chefs compete for $10,000 throughout 3 rounds. After each round, a chef gets “chopped.” Let’s look at the data.
tt.df <- tt$chopped
str(tt.df)## tibble [569 × 21] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ season : num [1:569] 1 1 1 1 1 1 1 1 1 1 ...
## $ season_episode : num [1:569] 1 2 3 4 5 6 7 8 9 10 ...
## $ series_episode : num [1:569] 1 2 3 4 5 6 7 8 9 10 ...
## $ episode_rating : num [1:569] 9.2 8.8 8.9 8.5 8.8 8.5 8.8 9 8.9 8.8 ...
## $ episode_name : chr [1:569] "Octopus, Duck, Animal Crackers" "Tofu, Blueberries, Oysters" "Avocado, Tahini, Bran Flakes" "Banana, Collard Greens, Grits" ...
## $ episode_notes : chr [1:569] "This is the first episode with only three official ingredients in a basket (dessert round). There would be no h"| __truncated__ "This is the first of a few episodes with five official ingredients in a basket (entrée round), as well as three"| __truncated__ NA "In the appetizer round, Chef Chuboda refused to use bananas in his dish, leading to his elimination. In the des"| __truncated__ ...
## $ air_date : chr [1:569] "January 13, 2009" "January 20, 2009" "January 27, 2009" "February 3, 2009" ...
## $ judge1 : chr [1:569] "Marc Murphy" "Aarón Sánchez" "Aarón Sánchez" "Scott Conant" ...
## $ judge2 : chr [1:569] "Alex Guarnaschelli" "Alex Guarnaschelli" "Alex Guarnaschelli" "Amanda Freitag" ...
## $ judge3 : chr [1:569] "Aarón Sánchez" "Marc Murphy" "Marc Murphy" "Geoffrey Zakarian" ...
## $ appetizer : chr [1:569] "baby octopus, bok choy, oyster sauce, smoked paprika" "firm tofu, tomato paste, prosciutto" "lump crab meat, dried shiitake mushrooms, pink grapefruit, bran cereal" "ground beef, wonton wrappers, cream of mushroom soup, bananas" ...
## $ entree : chr [1:569] "duck breast, green onions, ginger, honey" "daikon, pork loin, Napa cabbage, Thai chiles, Blue Point oysters" "ground beef, cannellini beans, tahini paste, grape jelly" "scallops, collard greens, anchovies, sour cream" ...
## $ dessert : chr [1:569] "prunes, animal crackers, cream cheese" "phyllo dough, gorgonzola cheese, pineapple rings, blueberries" "brioche, cantaloupe, pecans, avocados" "maple syrup, black plums, almond butter, walnuts, quick grits" ...
## $ contestant1 : chr [1:569] "Summer Kriegshauser" "Raymond Jackson" "Margaritte Malfy" "Sean Chudoba" ...
## $ contestant1_info: chr [1:569] "Private Chef and Nutrition Coach New York NY" "Private Caterer and Culinary Instructor Westchester County NY" "Executive Chef and Co-owner La Palapa New York NY" "Executive Chef Ayza Wine Bar New York NY" ...
## $ contestant2 : chr [1:569] "Perry Pollaci" "Klaus Kronsteiner" "Rachelle Rodwell" "Kyle Shadix" ...
## $ contestant2_info: chr [1:569] "Private Chef and Sous chef Bar Blanc New York NY" "Chef de cuisine Liberty National Golf Course Jersey City NJ" "Chef de cuisine SoHo Grand Hotel New York NY" "Chef Registered Dietician and Culinary Consultant New York NY" ...
## $ contestant3 : chr [1:569] "Katie Rosenhouse" "Christopher Jackson" "Chris Burke" "Luis Gonzales" ...
## $ contestant3_info: chr [1:569] "Pastry Chef Olana Restaurant New York NY" "Executive Chef and Owner Ted and Honey Brooklyn NY" "Private Chef New York NY" "Executive Chef Knickerbocker Bar & Grill New York NY" ...
## $ contestant4 : chr [1:569] "Sandy Davis" "Pippa Calland" "Andre Marrero" "Einat Admony" ...
## $ contestant4_info: chr [1:569] "Catering Chef Showstoppers Catering at Union Theological Seminary New York NY" "Owner and Chef Chef for Hire LLC Newville PA" "Chef tournant L’Atelier de Joël Robuchon New York NY" "Chef and Owner Taïm New York NY" ...
## - attr(*, "spec")=
## .. cols(
## .. season = col_double(),
## .. season_episode = col_double(),
## .. series_episode = col_double(),
## .. episode_rating = col_double(),
## .. episode_name = col_character(),
## .. episode_notes = col_character(),
## .. air_date = col_character(),
## .. judge1 = col_character(),
## .. judge2 = col_character(),
## .. judge3 = col_character(),
## .. appetizer = col_character(),
## .. entree = col_character(),
## .. dessert = col_character(),
## .. contestant1 = col_character(),
## .. contestant1_info = col_character(),
## .. contestant2 = col_character(),
## .. contestant2_info = col_character(),
## .. contestant3 = col_character(),
## .. contestant3_info = col_character(),
## .. contestant4 = col_character(),
## .. contestant4_info = col_character()
## .. )It appears the data is a little untidy. Based on a brief glance, it seems like the contestant’s state can be found in the information section. Also, each contestant has their own column. It would be slightly more tidy if we “pivot longer” and create a row for each candidate. The information should stay with the candidate, so I will merge the name and information columns and separate after the pivot is finished. Once this is done, it will be simple to extract the state from the candidate’s information section with str_trunc since the state is normally at the end of the description.
tt.transform <- tt.df %>%
unite(col = "contestant1", c(contestant1, contestant1_info), sep = " --- ") %>%
unite(col = "contestant2", c(contestant2, contestant2_info), sep = " --- ") %>%
unite(col = "contestant3", c(contestant3, contestant3_info), sep = " --- ") %>%
unite(col = "contestant4", c(contestant4, contestant4_info), sep = " --- ") %>%
pivot_longer(cols = c(contestant1, contestant2, contestant3, contestant4),
names_to = "contestant", values_to = "name") %>%
separate(name, into = c("name", "information"), sep = " --- ") %>%
mutate(state = str_trunc(information, width = 2,
side = "left", ellipsis = ""),
state = ifelse(state %in% state.abb, state, NA)) %>%
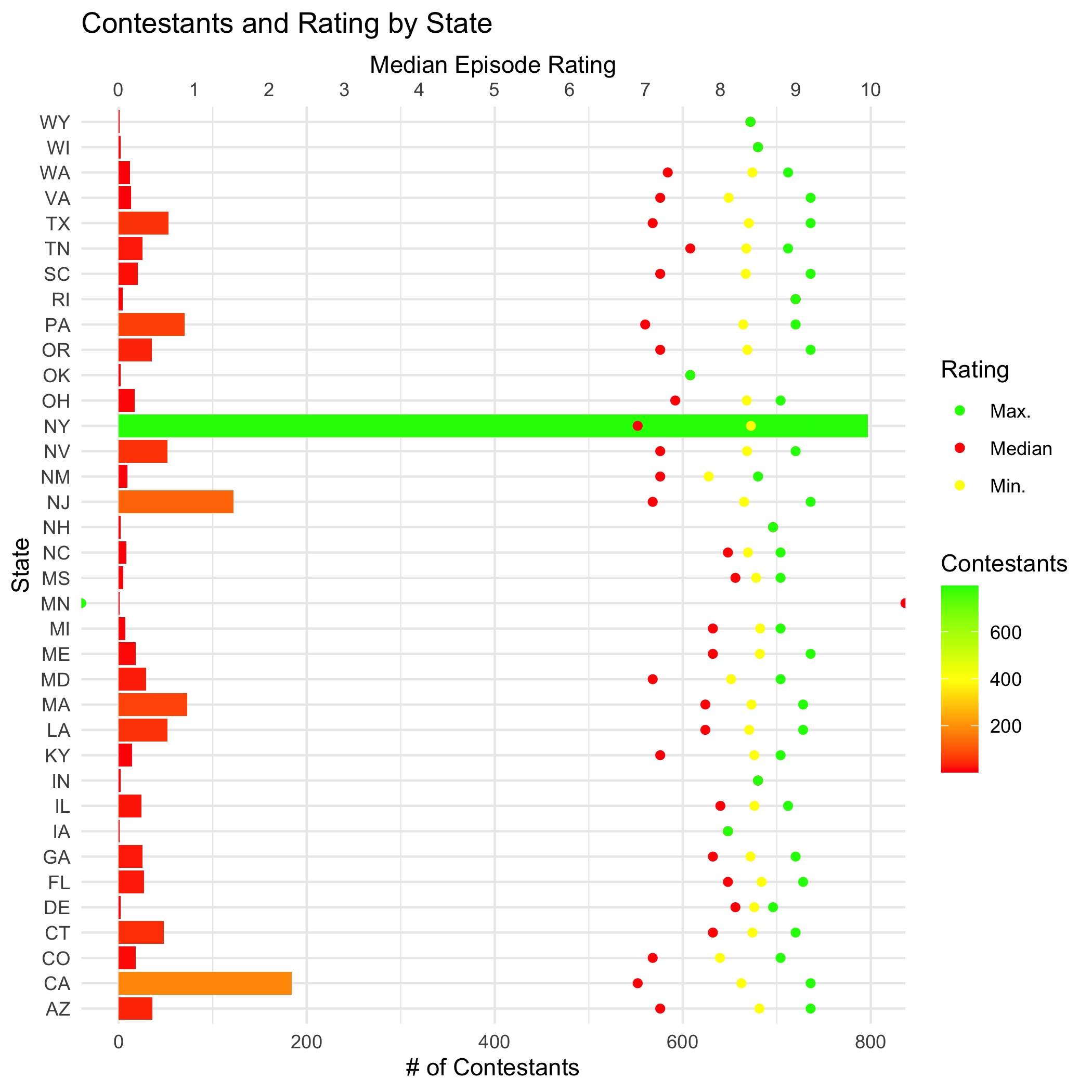
filter(!is.na(state))With this data, it appears an easy comparison can be made between the number of contestants from each state and the descriptive statistics on rating per state. I have never made a dual axis plot in R so it may be a fun analysis if we try to implement that functionality in some way.
tt.transform %>%
group_by(state) %>%
summarize(n = n(),
mean_episode_rating = mean(episode_rating, na.rm = TRUE),
median_episode_rating = median(episode_rating, na.rm = TRUE),
min_episode_rating = min(episode_rating, na.rm = TRUE),
max_episode_rating = max(episode_rating, na.rm = TRUE),
.groups = "keep") %>%
ggplot(aes(x = state)) +
geom_col(aes(y = n, fill = n)) +
geom_point(aes(y = mean_episode_rating * 80, color = "yellow")) +
geom_point(aes(y = min_episode_rating * 80, color = "red")) +
geom_point(aes(y = max_episode_rating * 80, color = "green")) +
scale_fill_gradient2(midpoint = 400, low = "red", mid = "yellow",
high = "green", space = "Lab" ) +
scale_y_continuous(
name = "# of Contestants",
sec.axis = sec_axis(~./80, name="Median Episode Rating",
breaks = 0:10)) +
labs(title = "Contestants and Rating by State",
x = "State", fill = "Contestants") +
scale_color_manual(name = 'Rating',
values =c('green'='green','yellow'='yellow','red'='red'),
labels = c('Max.','Median', 'Min.')) +
coord_flip() +
theme_minimal()## Warning in min(episode_rating, na.rm = TRUE): no non-missing arguments to min;
## returning Inf## Warning in max(episode_rating, na.rm = TRUE): no non-missing arguments to max;
## returning -Inf## Warning: Removed 1 rows containing missing values (geom_point).
I am satisfied with the end result. There were other directions this data could’ve been taken, such as looking at the individual ingredients used by show, but for a first attempt at a Tidy Tuesday, this graph makes me proud of how far I have come in my wrangling and visualization learning. Always keep learning!
Last Updated: 08/31/2020