
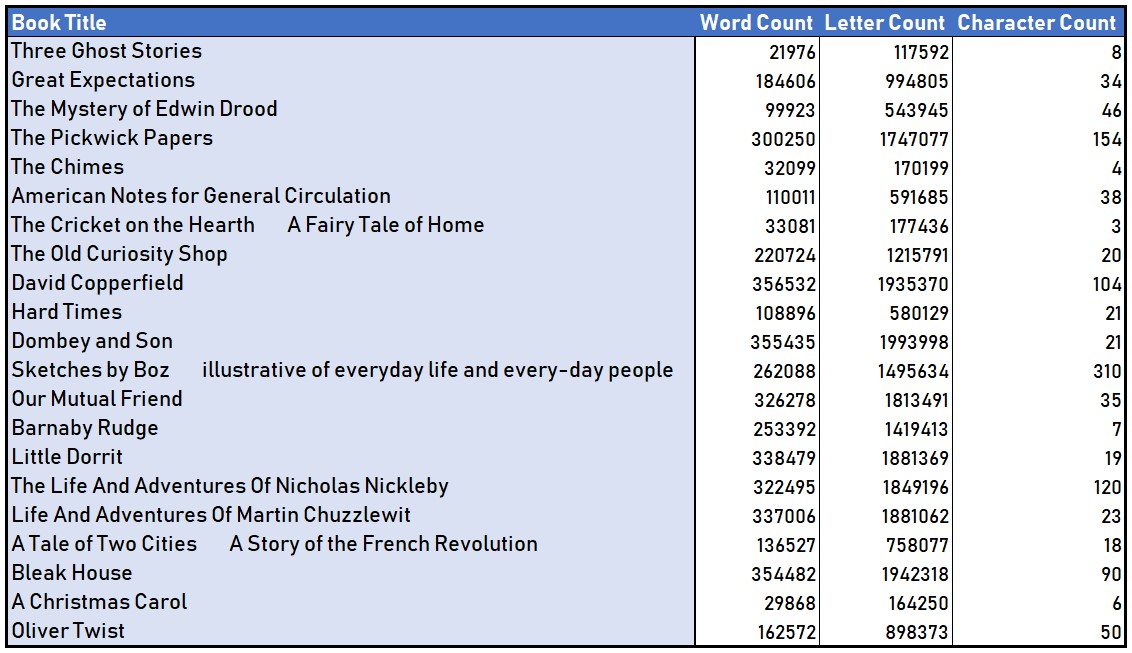
This was my first ever project in R. This was an assignment in my statistical computing class. I really enjoyed the process and learning about regular expressions. That is one subject I had never played around with before. This project showed me how powerful regular expressions can be. The point of this assignment was to parse twenty-one of Charles Dickens' books and return a data frame with the number of words, letters, and characters in each book.
Retrieving the title was simple. All files had text that said, "title:" right before every title and ended with a new line. Therefore, I just saved the text in between these items with the regular expression: "(T|t)itle:.+?\n". Word count and character count were also quite simple. The book was saved as a string so I was able to split by spacing and count the length of this new object. R has a nice function for letter count so I just used nchar for that. The tricky part was retrieving the number of characters in each novel.
The regular expression for character was going to be a beast. I knew that from the beginning. I knew each character would start with an honorific and then state the name. The tricky part was getting first name initials like Dr. R. Smith or Mrs. Susan B. Coldwell. The regular expression and its logic took about twice as long as coding the rest of the project. After some thought and questions to my peers, the regular expression in all its beauty was:
"(Mr\\.|Mister|Miss|Ms\\.|Ms|Doctor|Dr\\.)( [[:upper:]]([[:lower:]]*|\\.))+"
This is truly a masterpiece. Now, it still isn't perfect, but it works on the majority of name cases. Also, Mr. James Scott and Mr. Scott would still register as two separate characters, but overall, this is a fantastic solution. With that, I finished my first project in R and regular expressions. The output of the script is below. The files for all the code are on my GitHub. The link to the folder containing this project is below. I have left the script the same as the day I finished the assignment. Clearly, there are much better ways to go about some of the problems in this project, but I think it is nice to look back and see how far I have come in such a short amount of time.
Output:
 Last Updated: 10/11/2019
Last Updated: 10/11/2019